Ground has three main components: the Common Ground metamodel, Underground applications that support Ground, and Aboveground applications that consume data context from Ground. The existing service is composed of the APIs exposed by Common Ground and integrations with some underground services.
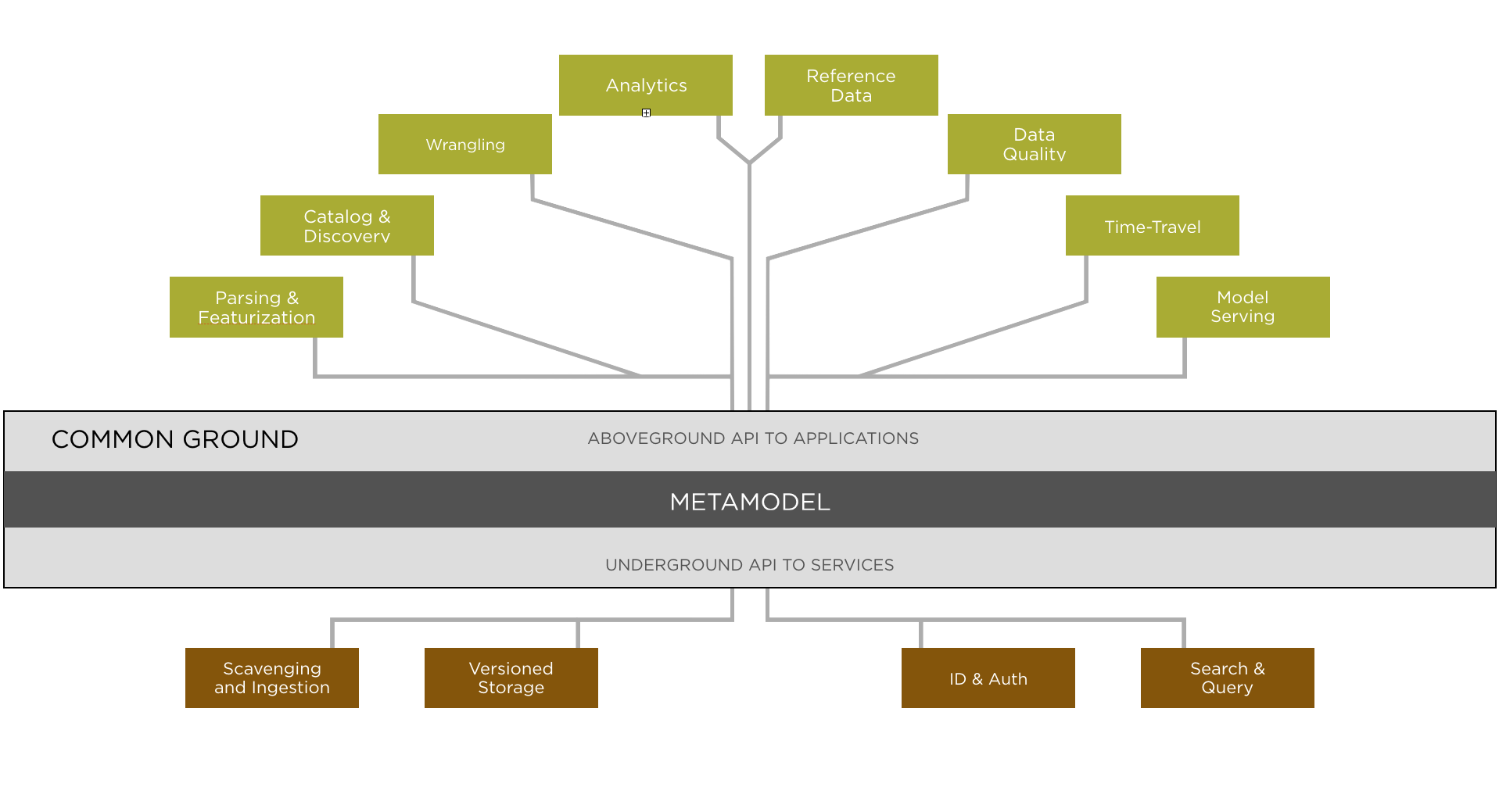
Common Ground
At the core of Common Ground is the metamodel, which has its own dedicated wiki page that explains it in much more detail than will be covered here. The one line summary of the model is as follows: A versioned, graph-based data model that treats data lineage as a first class citizen. In addition to the data model, Common Ground exposes a number of APIs to applications that allow them to publish, retrieve, and query their data context.
Underground Services
In order to provide functional data context services, there are 4 main components that Ground relies on.
Scavenging and Ingestion
In order to understand what data is in or added to a data lake, Ground will need to rely on a scavenging service to publish new events. As a first step and proof of concept, we have integrated with LinkedIn’s Gobblin project to be notified of new files added to HDFS. There is still work to be done here, where we would like to be able to notify aboveground or value-add services about new files and have them publish learned data.
Versioned Storage
Currently, we have built versioning shims over Postgres, Apache Cassandra, and Neo4j. We are evaluating performance and hope to settle on a recommended backing store soon.
ID & Auth
A data context system like Ground will need to have authentication and API authorization. We currently do not have any integration in this space, but we would like to design a pluggable API that can integrate with LDAP and similar authentication schemes that enterprises commonly use. There is a large space for more work here, including understanding how permissions interact with versioned data.
Search & Query
We currently rely on ElasticSearch to augment query performance and to retrieve tags efficiently. We hope our Query API will evolve as we generalize from a number of use cases, and this component might grow over time.
Aboveground Applications
In the architecture diagram above, we have listed a few applications that we believe would benefit from interfacing with a data context system. This is where you, the user, would build an application that talks to Ground through the Common Ground API. While we do not have any examples or best practices yet, we’re actively working on some and hope to be able to add some links here soon!